Data Structure
PanEvolution is a purely object-oriented module written in C++ with generic data structures like PanEngine, balancing performance, maintainability and scalability. The basic data structure for storing precipitation information in the system of interest is schematically shown in Figure 1.
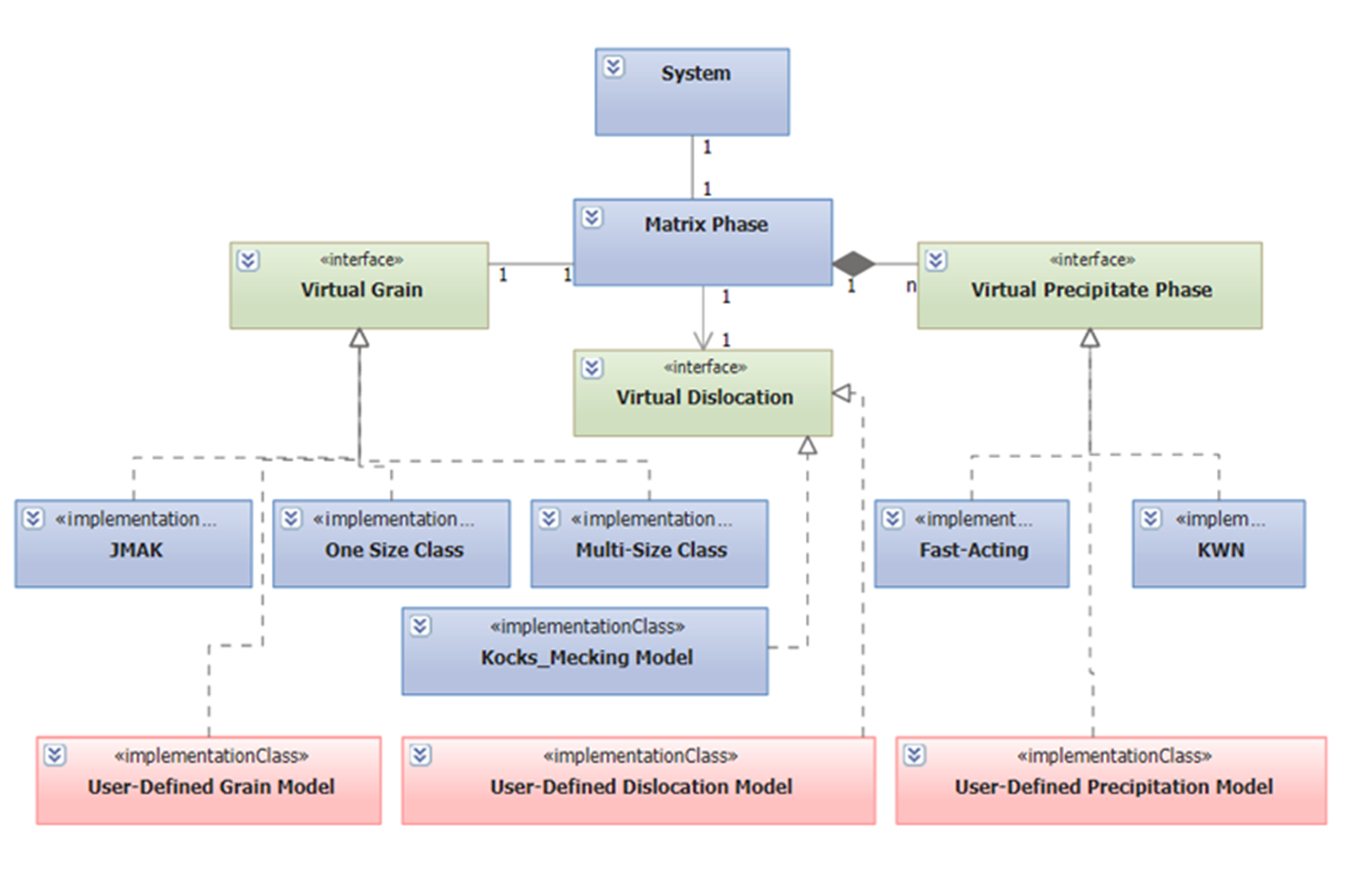
In general, a system contains a matrix phase, which is defined by a grain structure, and a number of precipitate phases. Different precipitate phases may behave differently, which should be described by different kinetic models. On the other hand, the calculation speed is directly related to the complexity of the model. It therefore requires multi-level models for different purposes. The current PanEvolution module includes two built-in models for precipitation: the Kampmann/Wagner Numerical (KWN) model and the Fast-Acting model. In order to simulate the grain growth/coarsening behavior, “one-size” and “multi-size” models have been developed. One unique advantage is that this generic data structure allows for concurrent simulation of grain growth and precipitation as well as easy integration of other precipitation, grain growth, dislocation density and recrystallization models with the PanEvolution module as shown in Figure 1. This gives users great flexibility in choosing the proper kinetic models, including their own user-defined models, for custom applications.
Based on the above data structure, input parameters for the matrix and its grain/precipitate phases are organized in “Extensible Markup Language” (XML) format, which is a standard markup language and well-known for its extendability. In accordance with the XML syntax, a set of well-designed tags are used to define the models for grain evolution and for every precipitate phase along with the corresponding model parameters, such as grain boundary energy, interfacial energy, molar volume and nucleation site parameter. The defined models and model parameters, which should be calibrated by the available experimental data, are stored in the so-called “Kinetic Parameters Database (KDB)”. In PanEvolution, two kinetic models known as the KWN and Fast-Acting were implemented for precipitation simulation and available for user’s choice. Both models can be used to simulate the co-precipitation of phases with various morphologies (sphere and lens), with concurrent processes of nucleation, growth and coarsening. With the selection of the KWN model, the particle size distributions (PSD) of various precipitate phases can be obtained in addition to the temporal evolution of the average size and volume fraction as obtained from the Fast-Acting model. Therefore, the KWN model is recommended by default.
It should be noted that in the KDB, models with closed-form equations can be defined to replace the built-in sub-models. This provides a database/script file level plug-in method for user-defined models.